Seaborn 内置数据集简介
学习数据分析或数据可视化时,我们最操心的莫过于不知道在哪里可以找到可以练习的数据集。Seaborn 自带了一些经典的数据集,用于方便我们进行基本的图表绘制。在联网状态下,我们可以通过 load_dataset() 函数来进行获取,首次下载之后会缓存到本地电脑中。
语法:
sns.load_dataset(name)说明:
name 是数据集的文件名,load_dataset() 函数会返回一个 DataFrame。对于 Seaborn 来说,它内置了 10 多个数据集,我们可以通过 “点击这里” (需要科学上网)查看都有哪些数据集。其中常用的数据集有 5 个,说明分别如下。
- flights.csv:航空数据集,该文件记录了某航空公司 1949 ~ 1960 年每个月的乘客人数。
- tips.csv:餐厅数据集,该文件记录了某餐厅客人消费情况,包括总额、小费、客人信息等。
- penguins.csv:企鹅数据集,记录了南极洲 344 只企鹅的特征信息,包括性别、体重、所在岛屿、嘴喙长度、嘴喙深度、鳍足长度等。
- titanic.csv:泰坦尼克号数据集,该文件记录了泰坦尼克号乘客的信息,包括性别、年龄、是否生存等。
- iris.csv:鸢尾花数据集,记录了 150 个鸢尾花的特征信息,包括花萼长度、花萼宽度、花瓣长度、花瓣宽度等。
对于 Seaborn 的内置数据集,我们需要特别说明一点:由于这些数据集是存放在国外的服务器中,所以在国内可能无法正常访问。
sns.load_dataset(name, data_home='data', cache=True)其中 name 是文件名(注意不需要带后缀),data_home 用于指定数据集所处的目录,cache=True 表示进行缓存。如果我们设置 data_home='data',此时就应该把这些数据集放在当前项目下的 data 文件夹中,如下图所示。
如果想要快速查看 Seaborn 到底内置了哪些数据集,我们可以使用 sns.get_dataset_names() 函数来获取所有数据集的名称列表(注意:这也需要科学上网)。
print(sns.get_dataset_names())Seaborn 内置数据集案例
接下来,我们通过一个具体的案例来讲解 Seaborn 是如何使用内置数据集的。
示例:Seaborn 使用内置数据集
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 加载数据
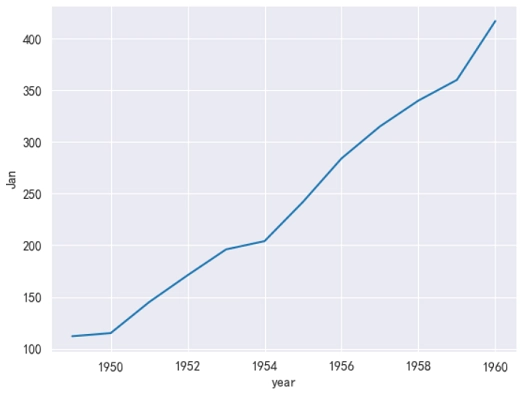
df = sns.load_dataset('flights', data_home='data', cache=True)
df = df.pivot_table(index='year', columns='month', values='passengers', observed=True)
# 绘制图表
sns.lineplot(data=df['Jan'])
# 显示
plt.show()运行之后,效果如下图所示。