


Seaborn 核密度图函数
核密度图和直方图的功能非常相似的,都是用于展示数据的分布情况,不过它们之间也有着以下 2 个方面的区别。
- 直方图使用 “条形” 来展示,核密度图使用 “曲线” 来展示。
- 直方图的纵坐标是数据的个数,核密度图的纵坐标是数据的密度。
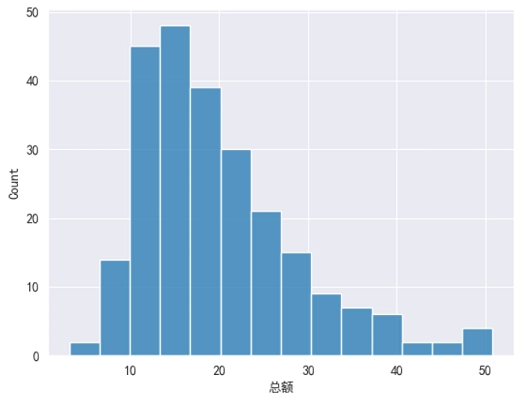
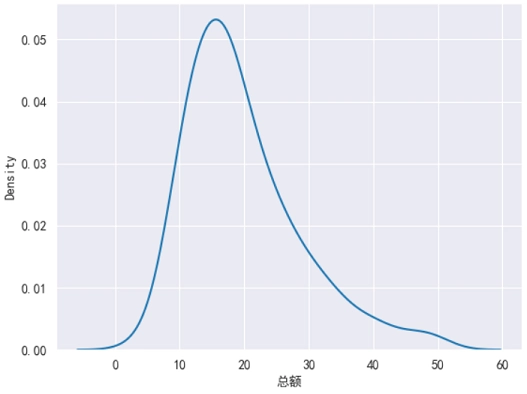
对于一个核密度图来说,它所占的面积等于 1。相比于直方图,核密度图可以生成一个不那么混乱、更易理解的图表。
在 Seaborn 中,我们可以使用 kdeplot() 函数来绘制一个核密度图。其中,kdeplot 是 “Kernel Desity Estimate(核密度估计)” 的缩写。
语法:
sns.kdeplot(data, x, y, hue, multiple, bw_adjust, cut, common_norm)说明:
kdeplot() 函数接收以下主要参数。
data(可选):用于定义数据部分,它是一个 DataFrame。x(可选):用于指定 DataFrame 的哪一列作为 x 轴坐标。y(可选):用于指定 DataFrame 的哪一列作为 y 轴坐标。
示例 1:Seaborn 绘制核密度图
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 数据
data = [
['张三', 24],
['李四', 18],
['王五', 37],
['小芳', 24],
['小红', 12],
['小明', 42],
['小华', 56],
['小莉', 67],
['小英', 45],
['小军', 82]
]
df = pd.DataFrame(data, columns=['姓名', '年龄'])
# 绘图
sns.kdeplot(data=df, x='年龄')
# 显示
plt.show()运行之后,效果如下图所示。
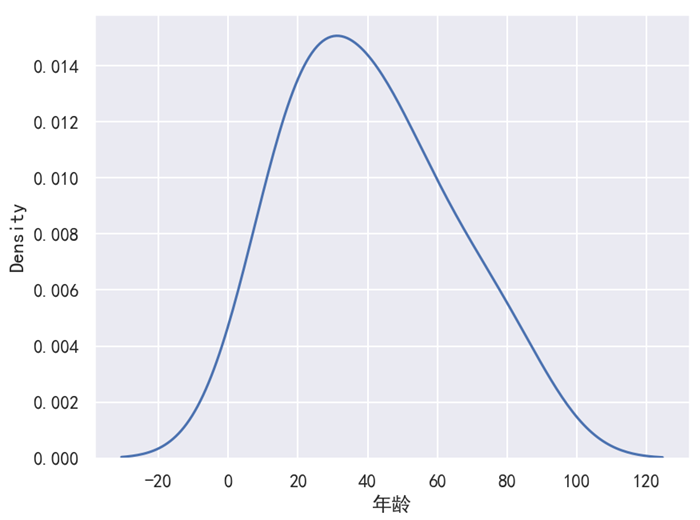
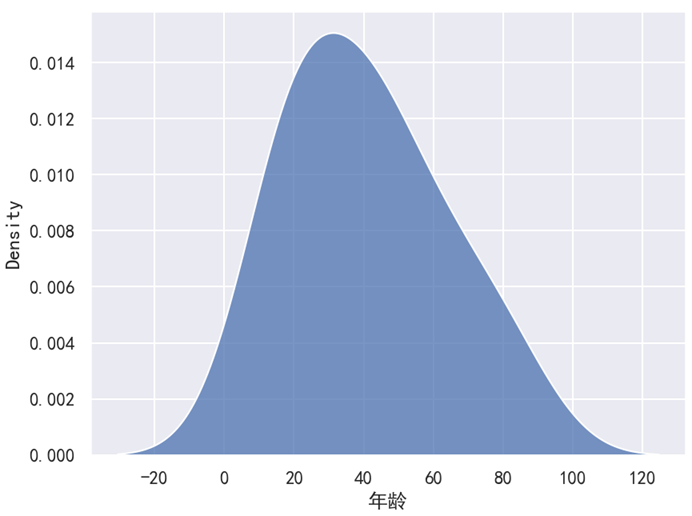
分析:
对于这个例子来说,x 轴的年龄,y 轴是年龄所占的百分比,然后整个面积刚好就是 1(百分之百)。这里所说的面积,指的是如下图所示的面积。对于核密度图来说,它的 y 轴表示的是一个密度,所以才叫做 “核密度图” 嘛。
Seaborn 核密度图案例
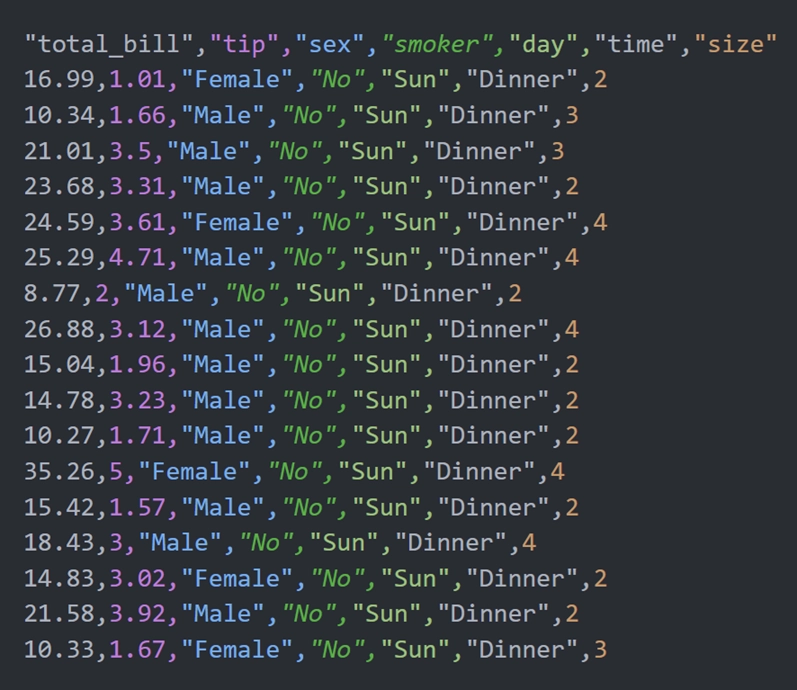
Seaborn 内置了一个数据集 tips,该数据集保存的是某餐厅的营业情况,包括账单、小费、客人信息等,部分内容如下图所示。需要说明的是,“size” 这一列指的是客人订的餐桌类型,比如有些是 2 人桌、有些是 3 人桌等。
示例 2:基本核密度图
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 加载内置数据集
df = sns.load_dataset('tips')
# 重命名列
column_map = {
'total_bill': '账单',
'tip': '小费',
'sex': '性别',
'smoker': '是否吸烟',
'day': '星期',
'time': '餐段',
'size': '人数'
}
df.rename(columns=column_map, inplace=True)
# 绘制图表
sns.kdeplot(data=df, x='账单')
# 显示
plt.show()运行之后,效果如下图所示。
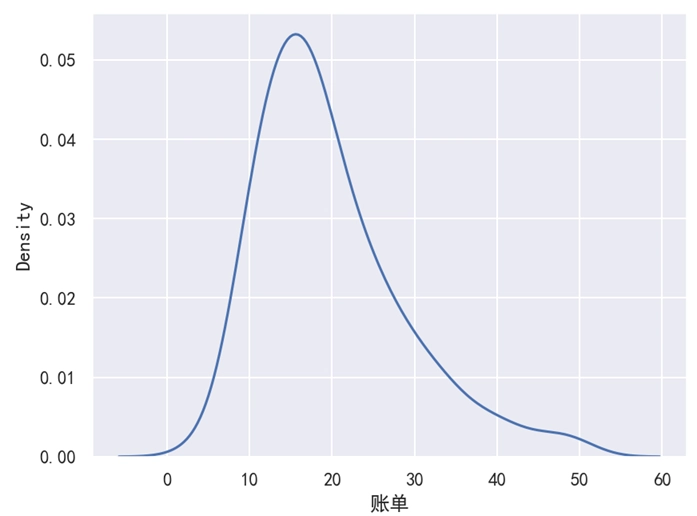
分析:
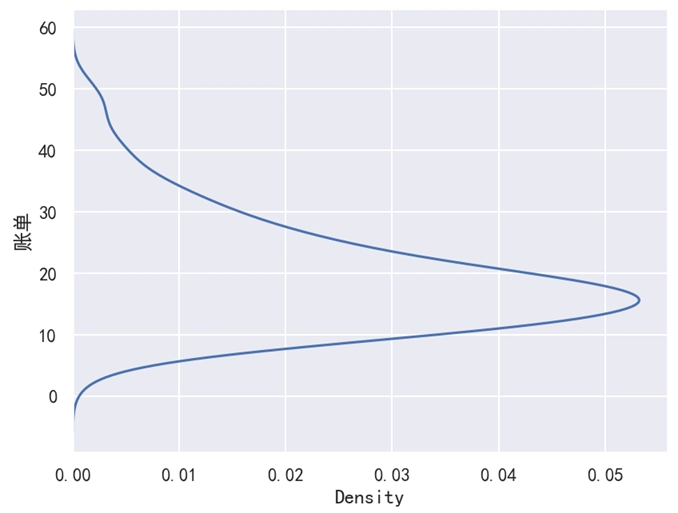
默认情况下,核密度图是纵向显示。如果想要横向显示,我们就不是使用 x 参数了,而是使用 y 参数。将 x='账单' 改为 y='账单' 之后,此时效果如下图所示。
示例 3:添加区分
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 加载内置数据集
df = sns.load_dataset('tips')
# 重命名列
column_map = {
'total_bill': '账单',
'tip': '小费',
'sex': '性别',
'smoker': '是否吸烟',
'day': '星期',
'time': '餐段',
'size': '人数'
}
df.rename(columns=column_map, inplace=True)
# 绘制图表
sns.kdeplot(data=df, x='账单', hue='餐段')
# 显示
plt.show()运行之后,效果如下图所示。
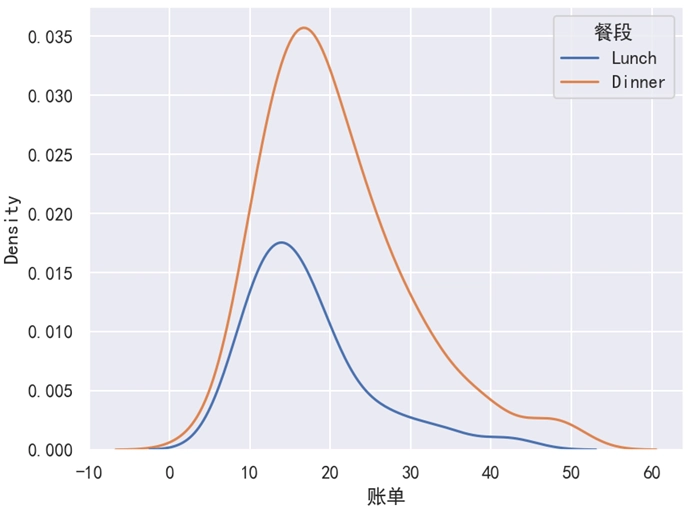
分析:
对于这个例子来说,两个部分的面积之和为 1。需要注意的是,kdeplot() 函数也只有 hue 参数,而没有 style 和 size 这 2 个参数。
上面是使用 “曲线” 的方式来展示,如果想要使用 “面积” 的方式来展示,我们可以使用 multiple='stack' 这个参数来实现。修改后的代码如下,此时效果如下图所示。
sns.kdeplot(data=df, x='账单', hue='餐段', multiple='stack')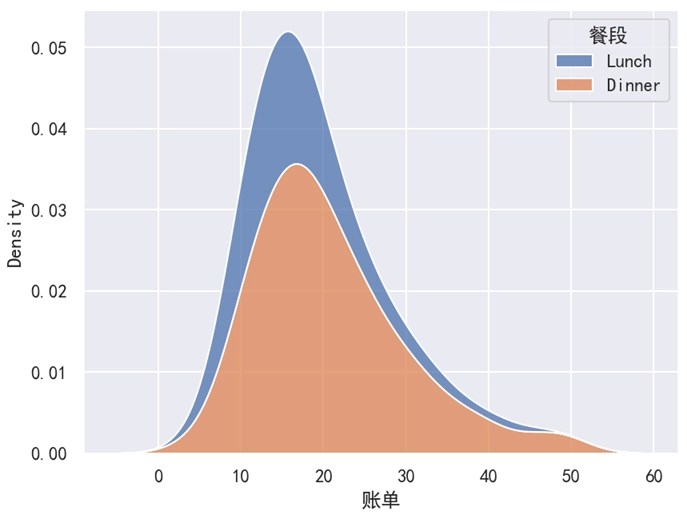
如果想要使用整个画布进行分布,我们可以使用 multiple='fill' 这个参数来实现。修改后的代码如下,此时效果如下图所示。
sns.kdeplot(data=df, x='账单', hue='餐段', multiple='fill')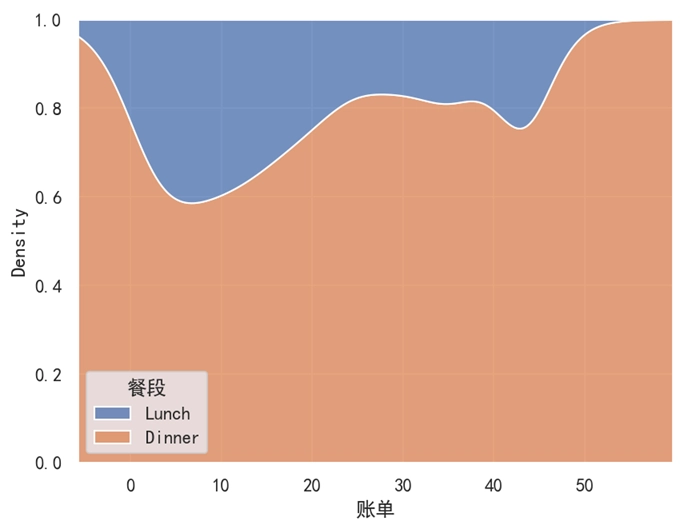
示例 4:曲线坡度
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 加载内置数据集
df = sns.load_dataset('tips')
# 重命名列
column_map = {
'total_bill': '账单',
'tip': '小费',
'sex': '性别',
'smoker': '是否吸烟',
'day': '星期',
'time': '餐段',
'size': '人数'
}
df.rename(columns=column_map, inplace=True)
# 绘制图表
sns.kdeplot(data=df, x='账单', bw_adjust=0.2)
# 显示
plt.show()运行之后,效果如下图所示。
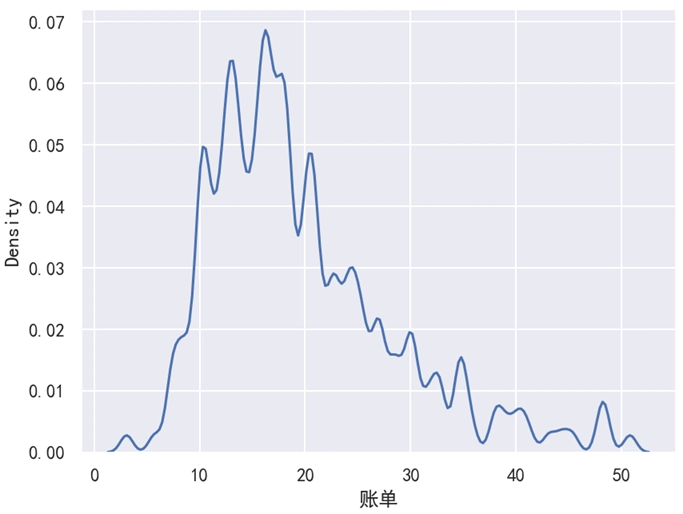
分析:
如果想要使用不同坡度的曲线来表示数据的分布情况,我们可以使用 bw_adjust 这个参数来实现。一般来说,当 bw_adjust 的值小于 1 时,表示使用较少平滑的曲线来表示,此时数据分布表示得更加精准。当 bw_adjust 的值大于 1 时,表示使用较多平滑的曲线来表示,此时数据分布表示得更加曲略。
当我们将 bw_adjust=0.2 改为 bw_ajust=5,修改后的代码如下,此时效果如下图所示。
sns.kdeplot(data=df, x='账单', bw_adjust=5)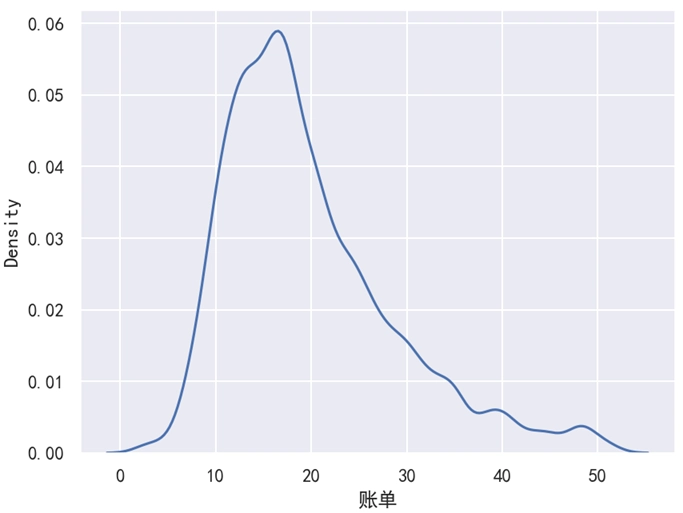
当 bw_adjust 的值过大时,数据展示就变得不精准。比如上面的 bw_adjust=5,此时还出现了负数部分。对于 “账单” 来说,不应该有负数才对,所以我们还得结合 cut=0 这个参数来把小于 0 的部分切除才行。修改后的代码如下,此时效果如下图所示。
sns.kdeplot(data=df, x='账单', bw_adjust=5.0, cut=0)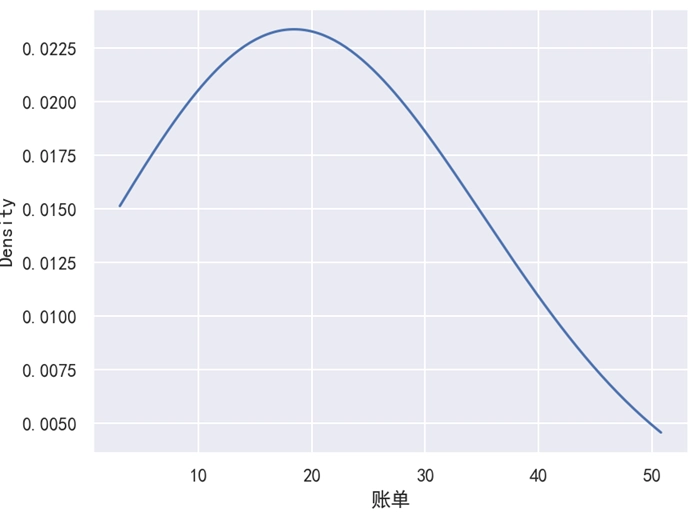
示例 5:独立计算面积
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 加载内置数据集
df = sns.load_dataset('tips')
# 重命名列
column_map = {
'total_bill': '账单',
'tip': '小费',
'sex': '性别',
'smoker': '是否吸烟',
'day': '星期',
'time': '餐段',
'size': '人数'
}
df.rename(columns=column_map, inplace=True)
# 绘制图表
sns.kdeplot(data=df, x='账单', hue='餐段', common_norm=False)
# 显示
plt.show()运行之后,效果如下图所示。
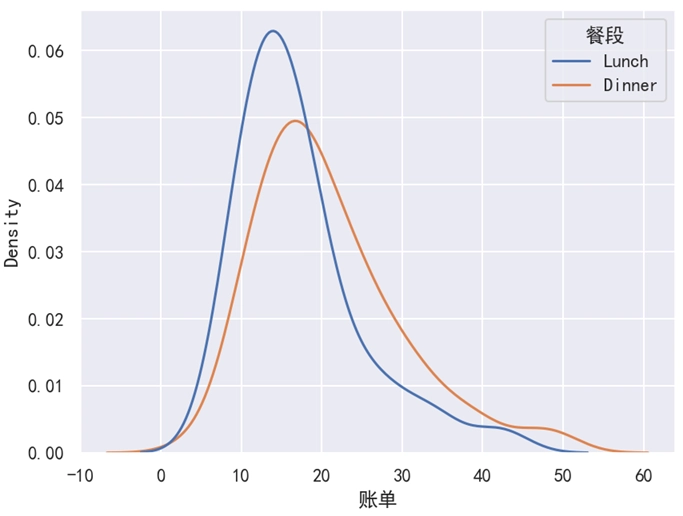
分析:
common_norm 参数的默认值为 True,此时所有类别下的总面积之和为 1。如果想要使得每一个类别都是独立的,面积都是 1,而不是总和为 1,此时我们可以使用 common_norm=False 来实现。
最后,我们来总结一下 kdeplot() 函数的参数,常用的如下表所示。
| 参数 | 说明 |
|---|---|
| data | 数据部分 |
| x | x 轴坐标 |
| y | y 轴坐标 |
| hue | 添加区分(颜色) |
| multiple='stack' | 堆叠显示(面积图) |
| multiple='fill' | 填充显示 |
| bw_adjust | 曲线平滑度 |
| cut=0 | 截断范围(0表示截断在数据极值处) |
| common_norm=False | 独立计算面积 |
