


Seaborn 直方图函数
直方图和柱状图十分相似,不过它们的功能是不一样的:柱状图用于展示数据大小,而直方图用于展示数据个数(频率)。
直方图适用于展示数值变量的分布情况,它在以下情况下特别有用。
- 展示数据的分布形态(例如,正态分布、偏态分布)。
- 识别数据中的峰值和异常值。
- 比较不同组数据的分布情况。
不过直方图也存在局限性,主要包括以下方面。
- 不适合展示分类变量的分布。
- 柱子的宽度和位置会影响直方图的视觉效果。
在 Seaborn 中,我们可以使用 histplot() 函数来绘制一个直方图。其中,histplot 是 “histplot plot” 的缩写。
语法:
sns.histplot(data, x, y, bins, binwidth)说明:
histplot() 函数接收以下主要参数。
data(可选):用于定义数据部分,它是一个 DataFrame。x(可选):用于指定 DataFrame 的哪一列作为 x 轴坐标。y(可选):用于指定 DataFrame 的哪一列作为 y 轴坐标。bins(可选):表示根据什么范围进行分组。如果没有指定 bins,那么 Seaborn 就会自动分组。binwidth(可选):表示定义直方图柱子的宽度。
histplot() 函数会根据提供的 x 或 y 值将数据分成若干个区间(bin),并统计每个区间内数据点的数量,然后用柱形图的形式展示每个区间内数据点的数量。
示例 1:Seaborn 绘制直方图
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 数据
data = [
['张三', 24],
['李四', 18],
['王五', 37],
['小芳', 24],
['小红', 12],
['小明', 42],
['小华', 56],
['小莉', 67],
['小英', 45],
['小军', 82]
]
df = pd.DataFrame(data, columns=['姓名', '年龄'])
# 绘图
sns.histplot(data=df, x='年龄')
# 显示
plt.show()运行之后,效果如下图所示。
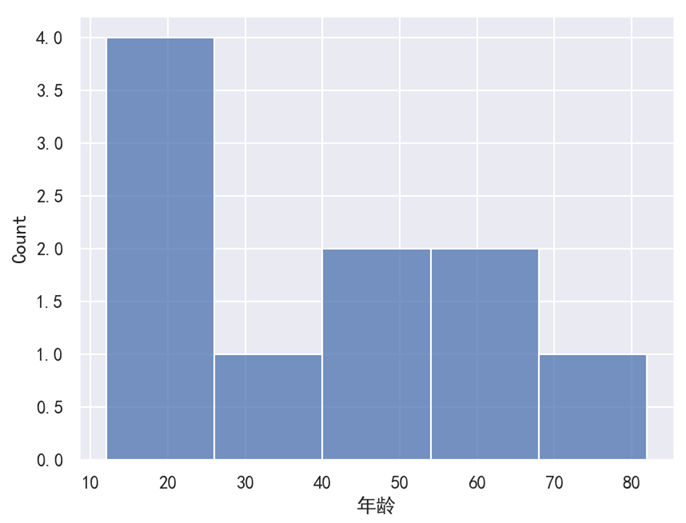
分析:
直方图用于统计处于各个区间数据的 “个数”,所以 y 轴标题显示的是 “count”(即个数)。如果没有指定 bins 这个参数,那么 Seaborn 就会自动帮你分组。不过从结果可以看出来,这个分组其实是有点 “乱来” 了,并不符合我们预期的效果。
示例 2:自定义分组
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 数据
data = [
['张三', 24],
['李四', 18],
['王五', 37],
['小芳', 24],
['小红', 12],
['小明', 42],
['小华', 56],
['小莉', 67],
['小英', 45],
['小军', 82]
]
df = pd.DataFrame(data, columns=['姓名', '年龄'])
# 绘图
sns.histplot(data=df, x='年龄', bins=[0, 20, 40, 60, 80, 100])
# 显示
plt.show()运行之后,效果如下图所示。
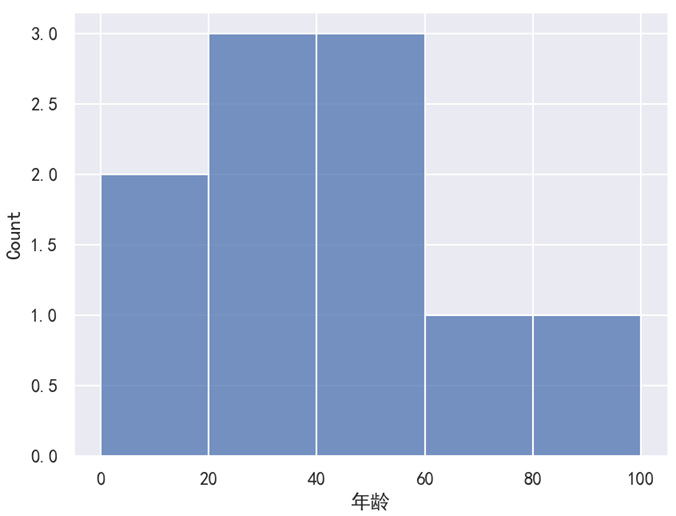
分析:
bins=[0, 20, 40, 60, 80, 100] 表示划分为 0~20、20~40、40~60、60~80、80~100 这 5 个区间,然后分别统计这 5 个区间年龄的个数。
除了 bins 这个参数之外,我们还可以使用 binwidth 来指定每一个区间的宽度。当我们改为下面这一句代码时,此时效果如下图所示。
sns.histplot(data=df, x='年龄', binwidth=20)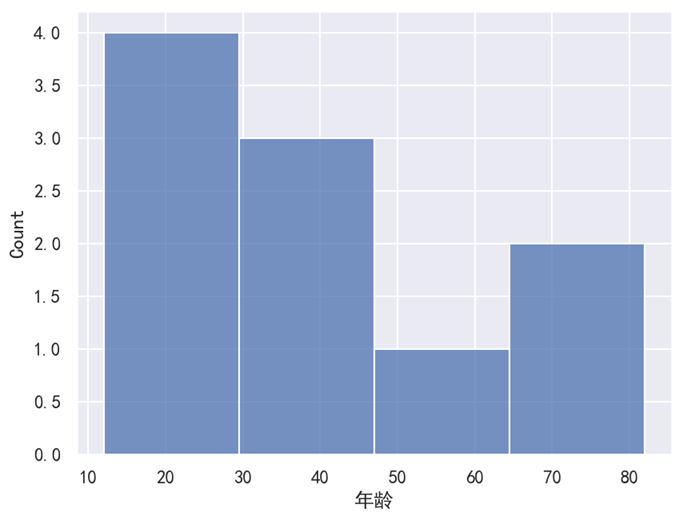
binwidth=20 表示指定区间的宽度为 20,需要注意的是,第 1 个区间并不是从 0 开始的,而是从最小的数据开始算起。由于上面最小的数据是 12,所以第 1 个区间是 12 ~ 32,然后第 2 个区间是 32 ~ 52…… 直到把所有数据都包含了。第 4 个区间是 72 ~ 92,此时已经把所有数据包含进去了,Seaborn 就结束区间的划分。
binwidth 参数这种方式来划分区间,弊端比较大,因为它并不是从 0 开始计算的。所以在实际开发中,最好的方式还是使用 bins 参数来实现分组。
Seaborn 直方图案例
Seaborn 内置了一个数据集 penguins,该数据集保存的是 344 只企鹅的相关数据,包括种类、岛屿、性别、体重等,部分内容如下图所示。需要注意的是,penguins 数据中存在一定的缺失值,不过这并不会影响我们绘制图表。
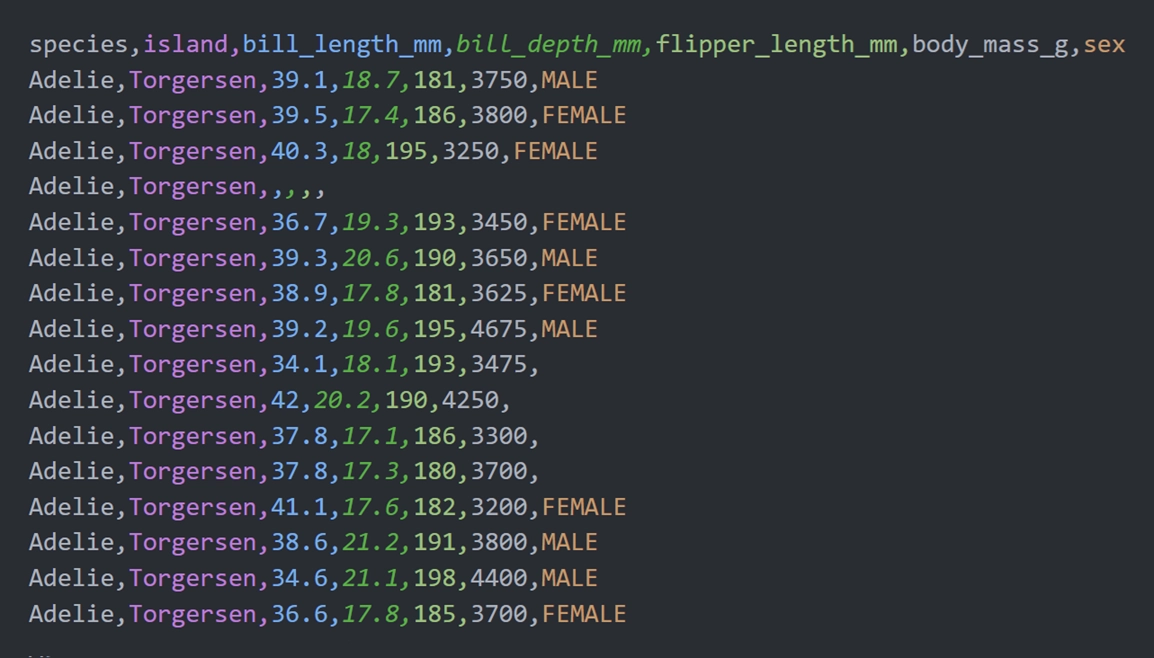
示例 3:基本直方图
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 加载内置数据集
df = sns.load_dataset('penguins')
# 重命名列
column_map = {
'species': '种类',
'island': '岛屿',
'bill_length_mm': '喙长',
'bill_depth_mm': '喙深',
'flipper_length_mm': '鳍长',
'body_mass_g': '体重',
'sex': '性别'
}
df.rename(columns=column_map, inplace=True)
# 绘制图表
sns.histplot(data=df, x='体重')
# 显示
plt.show()运行之后,效果如下图所示。
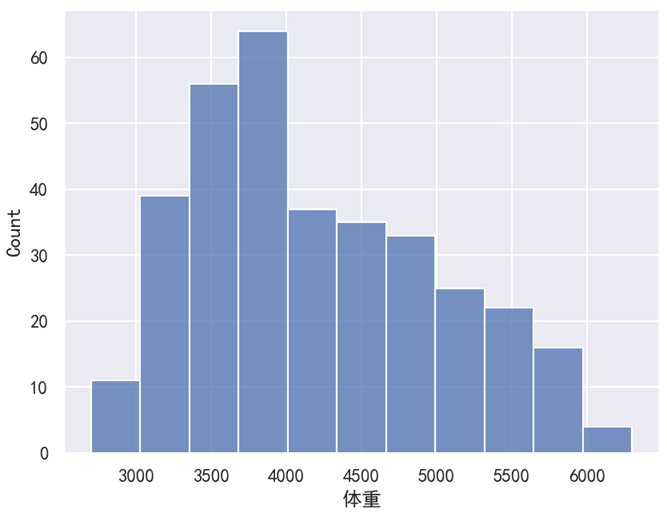
分析:
对于这个例子来说,直方图的 x 轴是 “体重”,然后 y 轴是每一个区间对应的 “数量(count)”。由于这里设置的是 x='体重',所以直方图是纵向的。如果想要改成横向的,我们只需要把 x='体重' 改为 y='体重' 就可以了。修改后的代码如下,此时效果如下图所示。
sns.histplot(data=df, y='体重')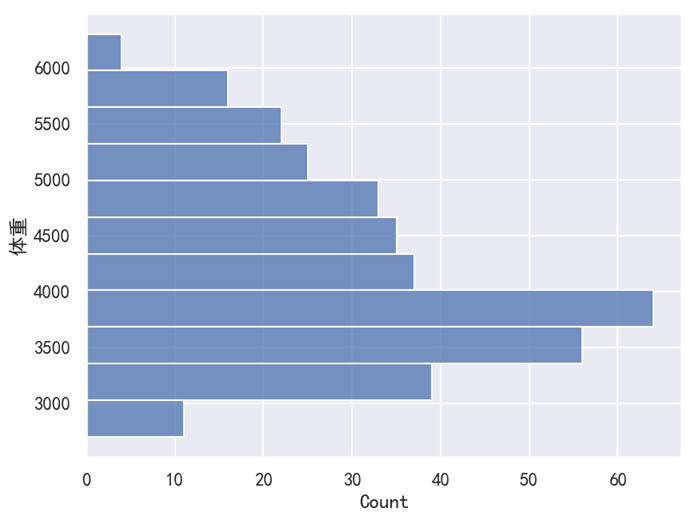
示例 4:添加核密度估计曲线
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 加载内置数据集
df = sns.load_dataset('penguins')
# 重命名列
column_map = {
'species': '种类',
'island': '岛屿',
'bill_length_mm': '喙长',
'bill_depth_mm': '喙深',
'flipper_length_mm': '鳍长',
'body_mass_g': '体重',
'sex': '性别'
}
df.rename(columns=column_map, inplace=True)
# 绘制图表
sns.histplot(data=df, x='体重', kde=True)
# 显示
plt.show()运行之后,效果如下图所示。
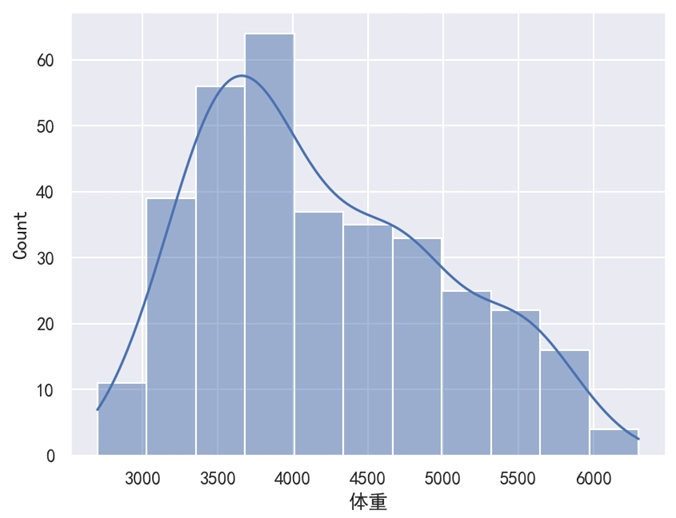
分析:
有时候我们不仅想看柱状的分布,还想看到平滑的分布曲线,此时只需要添加 kde=True 参数即可。
示例 5:添加区分
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 加载内置数据集
df = sns.load_dataset('penguins')
# 重命名列
column_map = {
'species': '种类',
'island': '岛屿',
'bill_length_mm': '喙长',
'bill_depth_mm': '喙深',
'flipper_length_mm': '鳍长',
'body_mass_g': '体重',
'sex': '性别'
}
df.rename(columns=column_map, inplace=True)
# 绘制图表
sns.histplot(data=df, x='体重', hue='性别')
# 显示
plt.show()运行之后,效果如下图所示。
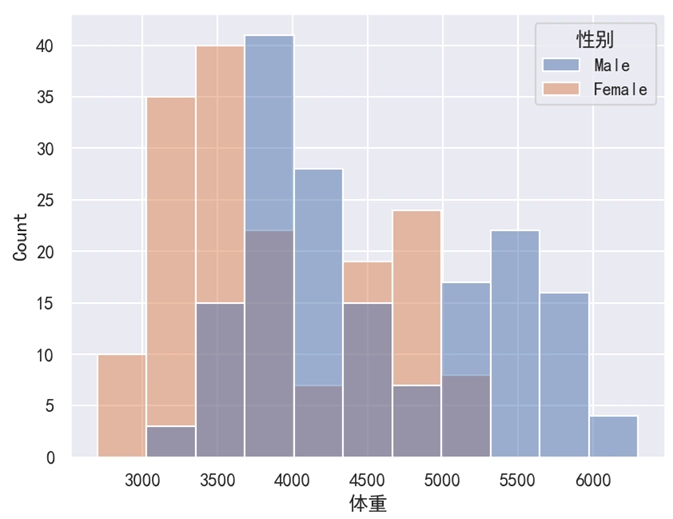
分析:
对于直方图来说,我们只能使用 hue 参数,而不能使用 style 或 size 这 2 个参数。histplot() 函数和 barplot() 函数一样,都是只有 hue 参数,而没有 style 和 size 这 2 个参数。
hue='性别' 表示使用 “性别” 这一列作为类别的区分。如果将 hue='性别' 改为 hue='种类',此时效果如下图所示。
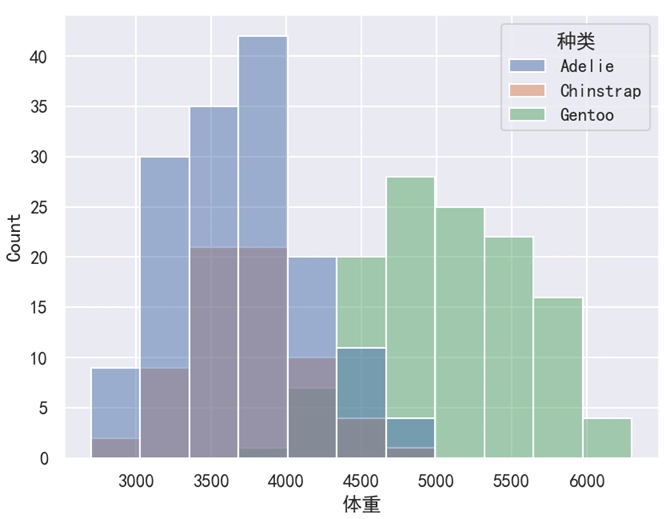
示例 6:堆叠显示
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 加载内置数据集
df = sns.load_dataset('penguins')
# 重命名列
column_map = {
'species': '种类',
'island': '岛屿',
'bill_length_mm': '喙长',
'bill_depth_mm': '喙深',
'flipper_length_mm': '鳍长',
'body_mass_g': '体重',
'sex': '性别'
}
df.rename(columns=column_map, inplace=True)
# 绘制图表
sns.histplot(data=df, x='体重', hue='性别', multiple='stack')
# 显示
plt.show()运行之后,效果如下图所示。
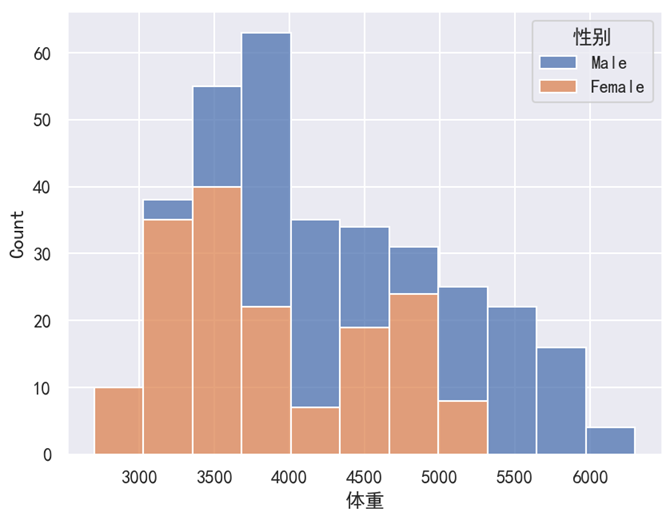
分析:
使用 hue 参数进行类别区分时,默认是使用 “分层” 的方式来显示(带有一定透明度)。实际上我们也可以使用 multiple='stack' 这个参数来使用 “堆叠” 的方式来显示。
示例 7:阶梯显示
import matplotlib.pyplot as plt
import seaborn as sns
# 设置
sns.set_theme(rc={'font.sans-serif': 'SimHei', 'axes.unicode_minus': False})
# 加载内置数据集
df = sns.load_dataset('penguins')
# 重命名列
column_map = {
'species': '种类',
'island': '岛屿',
'bill_length_mm': '喙长',
'bill_depth_mm': '喙深',
'flipper_length_mm': '鳍长',
'body_mass_g': '体重',
'sex': '性别'
}
df.rename(columns=column_map, inplace=True)
# 绘制图表
sns.histplot(data=df, x='体重', hue='种类', element='step')
# 显示
plt.show()运行之后,效果如下图所示。
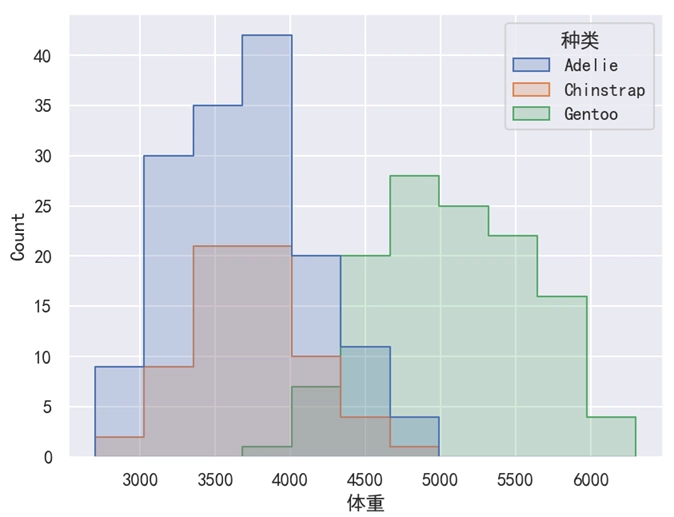
分析:
默认情况下,Seaborn 是使用 “条形” 这种方式来显示数据个数。不过我们可以使用 element='step' 这个参数来使用 “阶梯” 的方式来显示数据个数。
最后,我们来总结一下 histplot() 函数的参数,常用的如下表所示。
| 参数 | 说明 |
|---|---|
| data | 数据部分 |
| x | x 轴坐标 |
| y | y 轴坐标 |
| bins | 自定义分组 |
| binwidth | 定义柱子宽度 |
| kde=True | 添加核密度估计曲线 |
| hue | 添加区分(颜色) |
| multiple='stack' | 堆叠显示 |
| element='step' | 阶梯显示 |
