


CSV 文件是什么?
CSV,全称 “Comma-Separated Values(逗号分隔的值)”。CSV 文件是简化的电子表格(比如 Excel 表格),它保存的是纯文本。

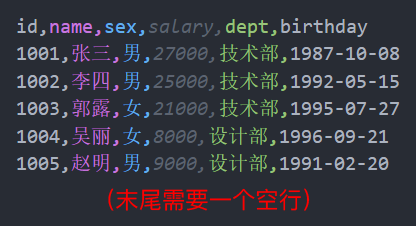
CSV 文件中的每行代表电子表格中的一行,每行中的单元格由逗号分隔。下面就是一个 CSV 文件的格式。第一行是列名,其他行是数据。
id,name,sex,salary,dept,birthday
1001,张三,男,27000,技术部,1987-10-08
1002,李四,男,25000,技术部,1992-05-15
1003,郭露,女,21000,技术部,1995-07-27
1004,吴丽,女,8000,设计部,1996-09-21
1005,赵明,男,9000,设计部,1991-02-20相比于 Excel 文件,CSV 少了很多功能,包括以下这些方面。
- 所有的值的类型都是字符串,没有其他类型。
- 没有字体大小或颜色的设置。
- 没有多个工作表。
- 不能合并单元格。
- 不能嵌入图像或图表。
- 不能指定单元格的宽度和高度。
但 CSV 文件的优势是简单易用,小伙伴们可以把它看成是一个 “简化版的 Excel 文件”。实际上,我们可以使用 Excel 软件来打开一个 CSV 文件,你可以自行试一下。
对于 CSV 文件,还有一点要特别注意:文件的最后需要有一个空行(本质上是一个换行符 “\n”),如下图所示。对于这个空行,我们需要清楚以下 3 点。
- 必须要有一个空行,如果没有空行,会导致比较多问题。
- 只能有一个空行,而不能有多个空行。
- 在统计有效数据的行数时,这个空行是不会被统计进去的。
Python 如何读取 CSV 文件?
在 Python 中,如果想要读取 CSV 文件,常用的是使用以下 2 种方式来实现。
- 使用 csv 模块。
- 使用 pandas 库。
1. 使用 csv 模块读取 CSV 文件
在 Python 中,我们可以使用 csv 模块的 reader() 函数来读取一个 CSV 文件。其中,csv 模块是 Python 自带的,不需要安装就可以直接使用它。
语法:
import csv
with open(路径, 'r', encoding='utf-8') as f:
reader = csv.reader(f)
……说明:
想要读取一个 CSV 文件,首先需要使用 open() 函数来打开这个 CSV 文件,这和打开任何其他文本文件是一样的。然后将 open() 函数返回的 File 对象作为参数传递给 reader() 函数。其中,reader() 函数会返回一个 Reader 对象,使用 Reader 对象可以让你访问 CSV 文件中的每一行。
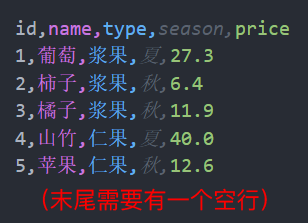
在当前项目下创建一个 data 文件夹,并且往 data 文件夹中添加一个 fruits.csv 文件,项目结构如下图 1 所示。其中,fruits.csv 中的内容如图 2 所示。需要注意的是,fruits.csv 最后必须要有一个空行。
示例 1:Python 读取 CSV
import csv
with open('data/fruits.csv', 'r', encoding='utf-8') as f:
reader = csv.reader(f)
data = list(reader)
print(data)运行结果如下。
[['id', 'name', 'type', 'season', 'price'], ['1', '葡萄', '浆果', '夏', '27.3'], ['2', '柿子', '浆果', '秋', '6.4'], ['3', '橘子', '浆果', '秋', '11.9'], ['4', '山竹', '仁果', '夏', '40.0'], ['5', '苹果', '仁果', '秋', '12.6']]分析:
想要访问 Reader 对象中的数据,最简单的办法就是使用 list() 函数将其转换为一个列表。该列表是一个二维列表,然后就可以通过下标的方式来获取某一个单元格的值。
提示: open() 函数可以打开任意纯文本文件,而 TXT、CSV、JSON 等文件等都属于纯文本文件。
使用 print() 函数进行输出,当数据比较多时,展示效果并不理想。想要更好的阅读格式,我们可以使用 Python 自带的一个格式化函数:pprint()。使用 from pprint import pprint 导入,就可以直接使用了。
import csv
from pprint import pprint
with open('data/fruits.csv', 'r', encoding='utf-8') as f:
reader = csv.reader(f)
data = list(reader)
pprint(data)再次运行后结果如下,此时的阅读体验就要好多了。
[['id', 'name', 'type', 'season', 'price'],
['1', '葡萄', '浆果', '夏', '27.3'],
['2', '柿子', '浆果', '秋', '6.4'],
['3', '橘子', '浆果', '秋', '11.9'],
['4', '山竹', '仁果', '夏', '40.0'],
['5', '苹果', '仁果', '秋', '12.6']]示例 2:获取 CSV 某一列的值
import csv
with open('data/fruits.csv', 'r', encoding='utf-8') as f:
reader = csv.reader(f)
fruits = list(reader)
del fruits[0] # 删除第一行,即列名那一行
for fruit in fruits:
print(fruit[1])运行结果如下。
葡萄
柿子
橘子
山竹
苹果示例 3:访问 CSV 每一行
import csv
with open('data/fruits.csv', 'r', encoding='utf-8') as f:
reader = csv.reader(f)
for row in reader:
result = f'第{reader.line_num}行:{row}'
print(result)运行结果如下。
第 1 行:['id', 'name', 'type', 'season', 'price']
第 2 行:['1', '葡萄', '浆果', '夏', '27.3']
第 3 行:['2', '柿子', '浆果', '秋', '6.4']
第 4 行:['3', '橘子', '浆果', '秋', '11.9']
第 5 行:['4', '山竹', '仁果', '夏', '40.0']
第 6 行:['5', '苹果', '仁果', '秋', '12.6']分析:
这里的 reader 是一个可迭代对象,可以使用 for 循环 来遍历它。它的每一个元素代表的就是一行数据。对于数据量比较大的 CSV 文件来说,我们可以在一个 for 循环中使用 Reader 对象,这样能够避免将整个文件一次性装入内存。
此外,如果想要取得行号(即第几行),我们可以使用 Reader 对象的 line_num 属性来获取。
2. 使用 pandas 库读取 CSV 文件
在 Python 中,我们还可以使用 pandas 库的 read_csv() 函数来读取一个 CSV 文件。Pandas 是第三方库,在使用之前需要安装它。
pip install pandas语法:
pd.read_csv(path, index_col=m)说明:
read_csv() 函数接收以下 2 个参数。
path(必选):表示文件的路径。index_col(可选):用于将某一列指定为 “行名”(也叫索引列),比如 index_col=0 表示指定第一列为行名。
read_csv() 函数会返回一个 DataFrame 对象,也就是会将 CSV 文件的数据转换成一个 DataFrame 对象。
示例 4:pandas 读取 CSV 文件
import pandas as pd
df = pd.read_csv('data/fruits.csv')
pd.set_option('display.unicode.east_asian_width', True)
print(df)
print(type(df))运行结果如下。
id name type season price
0 1 葡萄 浆果 夏 27.3
1 2 柿子 浆果 秋 6.4
2 3 橘子 浆果 秋 11.9
3 4 山竹 仁果 夏 40.0
4 5 苹果 仁果 秋 12.6
<class 'pandas.core.frame.DataFrame'>分析:
默认情况下,当使用 read_csv() 方法读取一个 CSV 文件时,会使用递增的数字(0、1、2...、n)来当做行名(即索引列)。如果想要指定 “id” 这一列作为新的行名,我们可以使用 index_col=0 来实现,请看下面例子。
示例 5:指定某一列作为行索引
import pandas as pd
# 使用 index_col=0 将第一列(id)作为行索引
df = pd.read_csv('data/fruits.csv', index_col=0)
pd.set_option('display.unicode.east_asian_width', True)
print(df)运行结果如下。
name type season price
id
1 葡萄 浆果 夏 27.3
2 柿子 浆果 秋 6.4
3 橘子 浆果 秋 11.9
4 山竹 仁果 夏 40.0
5 苹果 仁果 秋 12.6分析:
从结果可以看到,原本默认的 0、1、2、3、4 数字索引不见了,取而代之的是我们指定的 id 这一列充当了数据的行名。
提示: Pandas 是 Python 数据分析最重要的工具之一,想要更全面深入地了解它,可以学习我们即将上线的 Pandas 教程。
