


在 Python 中,如果想要写入 JSON 文件,同样可以使用以下 2 种方式来实现。
- 使用 json 模块。
- 使用 pandas 库。
使用 json 模块写入 JSON 文件
在 Python 中,我们可以使用 json 模块的 dump() 函数来把数据写入一个 JSON 文件。
语法:
import json
with open(路径, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False)
……说明:
首先需要使用 open() 函数来打开一个文件,这个和打开所有其他文本文件是一样的。但是在这里,我们不再是使用 File 对象的 write() 方法,而是将这个 File 对象传递给 dump() 方法。
dump() 方法接受 3 个参数:data 是一个 JSON 数据,f 是一个 File 对象。ensure_ascii=False 是一个可选参数,如果包含中文内容,就必须加上。
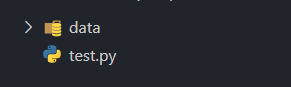
当前项目目录下有一个名为 “data” 的文件夹,整个项目结构如下图所示。
示例 1:Python 写入 JSON
import json
data = [
{ "id": 1, "name": "葡萄", "type": "浆果", "season": "夏", "price": 27.3 },
{ "id": 2, "name": "柿子", "type": "浆果", "season": "秋", "price": 6.4 },
{ "id": 3, "name": "橘子", "type": "浆果", "season": "秋", "price": 11.9 },
{ "id": 4, "name": "山竹", "type": "仁果", "season": "夏", "price": 40.0 },
{ "id": 5, "name": "苹果", "type": "仁果", "season": "秋", "price": 12.6 }
]
with open('data/fruits.json', 'w', encoding='utf-8') as f:
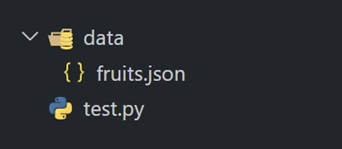
json.dump(data, f, ensure_ascii=False)运行代码之后,我们可以发现 data 文件夹中多了一个 fruits.json 文件,如下图 1 所示。打开 fruits.json 文件,其内容如下图 2 所示。

使用 pandas 库写入 JSON 文件
在 Python 中,我们还可以使用 pandas 库中的 to_json() 方法将数据导出到一个 JSON 文件中。其中,to_json() 是 DataFrame 对象的一个方法。
语法:
df.to_json(path, index=布尔值 , header=布尔值 , force_ascii=布尔值)说明:
to_json() 方法接收以下 4 个参数。
path(必选):表示文件的路径。index(可选):表示是否输出行名(行缩进),默认值为 True(也就是会输出行名)。header(可选):表示是否输出列名,默认值为 True(也就是会输出列名)。force_ascii(可选):如果你的 JSON 数据包含中文,就必须加上 force_ascii=False,否则就可能会出现乱码。
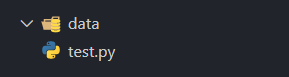
特别注意一点:read_json() 是 Pandas 的一个方法,而 to_json() 是 DataFrame 的一个方法。接下来我们清空 data 文件夹,此时整个项目结构如下图所示。
示例 2:pandas 写入 JSON
import pandas as pd
data = [
{ "id": 1, "name": "葡萄", "type": "浆果", "season": "夏", "price": 27.3 },
{ "id": 2, "name": "柿子", "type": "浆果", "season": "秋", "price": 6.4 },
{ "id": 3, "name": "橘子", "type": "浆果", "season": "秋", "price": 11.9 },
{ "id": 4, "name": "山竹", "type": "仁果", "season": "夏", "price": 40.0 },
{ "id": 5, "name": "苹果", "type": "仁果", "season": "秋", "price": 12.6 }
]
df = pd.DataFrame(data)
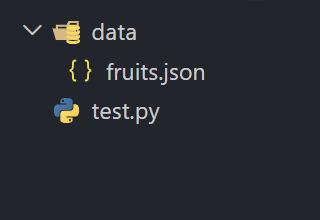
df.to_json('data/fruits.json', force_ascii=False)运行代码之后,我们可以发现 data 文件夹中多了一个 fruits.json 文件,如下图所示。
分析:
打开 fruits.json,其内容如下所示。
{
"id": { "0": 1, "1": 2, "2": 3, "3": 4, "4": 5 },
"name": { "0": "葡萄", "1": "柿子", "2": "橘子", "3": "山竹", "4": "苹果" },
"type": { "0": "浆果", "1": "浆果", "2": "浆果", "3": "仁果", "4": "仁果" },
"season": { "0": "夏", "1": "秋", "2": "秋", "3": "夏", "4": "秋" },
"price": { "0": 27.3, "1": 6.4, "2": 11.9, "3": 40.0, "4": 12.6 }
}上面其实是把行名也写进来了,很多时候我们并不希望 JSON 文件有这种连续整数的行名,此时可以使用 index=False 这个参数,代码修改如下。
df.to_json('data/fruits.json', index=False, force_ascii=False)再次运行代码之后,发现却报错了,控制台输出如下。也就是说,如果想要设置 index=False,我们还要设置 orient='split' 或 orient='table' 才行。
(报错)ValueError: 'index=False' is only valid when 'orient' is 'split' or 'table'示例 3:orient="split"
import pandas as pd
data = [
{ "id": 1, "name": "葡萄", "type": "浆果", "season": "夏", "price": 27.3 },
{ "id": 2, "name": "柿子", "type": "浆果", "season": "秋", "price": 6.4 },
{ "id": 3, "name": "橘子", "type": "浆果", "season": "秋", "price": 11.9 },
{ "id": 4, "name": "山竹", "type": "仁果", "season": "夏", "price": 40.0 },
{ "id": 5, "name": "苹果", "type": "仁果", "season": "秋", "price": 12.6 }
]
df = pd.DataFrame(data)
df.to_json('data/fruits.json', index=False, orient='split', force_ascii=False)运行代码之后,就不会报错了。其中 fruits.json 内容如下。
{
"columns": ["id", "name", "type", "season", "price"],
"data": [
[1, "葡萄", "浆果", "夏", 27.3],
[2, "柿子", "浆果", "秋", 6.4],
[3, "橘子", "浆果", "秋", 11.9],
[4, "山竹", "仁果", "夏", 40.0],
[5, "苹果", "仁果", "秋", 12.6]
]
}