在 Python 中,写入 Excel 文件的方式有很多,但最推荐的还是使用 pandas 库来实现。在使用 pandas 之前,需要确保已经安装它以及处理 Excel 所需的底层引擎。
pip install pandas
pip install openpyxl在 Pandas 中,我们可以使用 to_excel() 方法将数据导出到一个 Excel 文件中。其中,to_excel() 是 DataFrame 对象的一个方法。
语法:
df.to_excel(path, index=布尔值, header=布尔值)说明:
to_excel() 方法接收以下 3 个参数。
path(必选):表示文件路径。index(可选):表示是否输出行名,默认值为 True(也就是会输出行名)。header(可选):表示是否输出列名,默认值为 True(也就是会输出列名)。
特别注意一点:上一节介绍的 read_excel() 是 Pandas 的一个函数,而 to_excel() 是 DataFrame 的一个方法。接下来,我们清空 data 文件夹,此时整个项目结构如下图所示。
示例:pandas 写入 Excel
import pandas as pd
data = [
[1,'葡萄', '浆果', '夏', 27.3],
[2,'柿子', '浆果', '秋', 6.4],
[3,'橘子', '浆果', '秋', 11.9],
[4,'山竹', '仁果', '夏', 40.0],
[5,'苹果', '仁果', '秋', 12.6],
]
df = pd.DataFrame(data, columns=['id', 'name', 'type', 'season', 'price'])
df.to_excel('data/fruits.xlsx')运行代码之后,我们可以发现 data 文件夹中多了一个 fruits.xlsx 文件,如下图 1 所示。其中,fruits.xlsx 的内容如下图 2 所示。
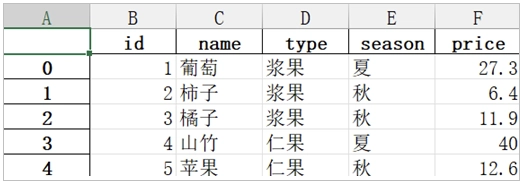
同样地,默认情况下 to_excel 会把列名和行名写入 Excel 文件中。如果不希望把行名写入,此时可以使用 index=False 参数,代码如下。
df.to_excel('data/fruits.xlsx', index=False)再次运行代码之后,打开 fruits.xlsx 文件,此时发现行名不见了,如下图所示。