


在 Python 中,如果想要写入 CSV 文件,同样可以使用以下 2 种方式来实现。
- 使用 csv 模块。
- 使用 pandas 库。
使用 csv 模块写入 CSV 文件
在 Python 中,我们可以使用 csv 模块的 writer() 函数来将数据写入一个 CSV 文件。
语法:
import csv
with open(路径, 'w', encoding='utf-8') as f:
writer = csv.writer(f)
……说明:
想要往 CSV 文件写入数据,首先也是需要使用 open() 函数来打开这个文件,注意此时使用的是 'w' 模式。如果想要以 “追加” 的方式写入,应该使用 'a' 模式。打开文件之后,接着使用 csv 模块的 writer() 函数来写入数据。
首先整理一下项目结构,当前项目下有一个 data 文件夹,整个项目的结构如下图所示。
示例 1:以覆盖的方式写入 CSV 文件
import csv
with open('data/fruits.csv', 'w', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow([1, '葡萄', '浆果', '夏', 27.3])
writer.writerow([2, '柿子', '浆果', '秋', 6.4])
writer.writerow([3, '橘子', '浆果', '秋', 11.9])
writer.writerow([4, '山竹', '仁果', '夏', 40.0])
writer.writerow([5, '苹果', '仁果', '秋', 12.6])运行代码之后,我们可以发现 data 文件夹中多了一个 fruits.csv 文件,如下图 1 所示。fruits.csv 文件内容如图 2 所示。
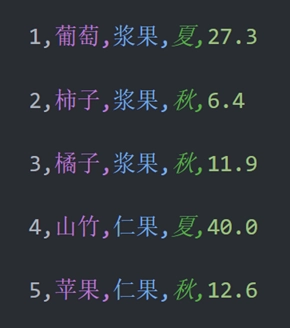
分析:
数据倒是添加进去了,却多了很多空行,这是怎么回事呢?想要解决这个问题,需要在 open() 函数中添加 newline='' 这个参数。
with open('data/fruits.csv', 'w', encoding='utf-8', newline='') as f:我们把 fruits.csv 重置成原来的数据,再次运行后的效果就是正常的了,如下图所示。

示例 2:以追加的方式写入 CSV 文件
import csv
with open('data/fruits.csv', 'a', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
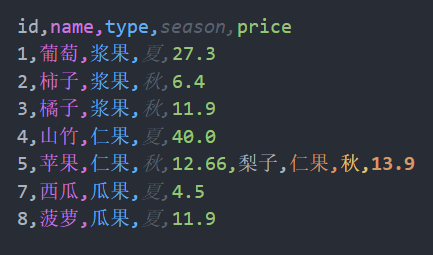
writer.writerow([6, '梨子', '仁果', '秋', 13.9])
writer.writerow([7, '西瓜', '瓜果', '夏', 4.5])
writer.writerow([8, '菠萝', '瓜果', '夏', 11.9])运行之后,打开 fruits.csv 文件,可以看到数据已经添加进去了,如下图所示。
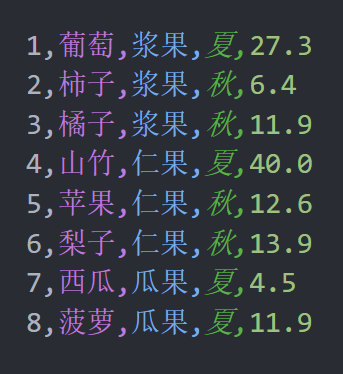
分析:
with open('data/fruits.csv', 'a', encoding='utf-8') as f:上面的 'a' 表示以追加的方式来写入文件,此时是在文件原内容的末尾追加新内容。
之前反复强调 CSV 文件最后要有一个空行,如果没有这个空行,又会怎么样呢?我们重塑 fruits.csv 成如下图 1 所示,并且把最后的空行删除。然后再去执行上面例子的代码,结果如下图 2 所示。
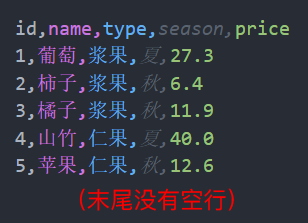
如果没有这一个空行,那么下一次追加的内容就会紧贴在已有数据的后面,而不是另起一行显示数据,这样得到的就不是预期结果了。所以在使用 CSV 文件格式时,请一定要记得在最后加上一个空行。
如何一次性写入多行数据?
在上面的例子中,我们是一行一行地调用 writerow() 来写入数据的。如果数据量很大,我们可以把所有数据放在一个 “二维列表” 中,然后使用 writerows() 方法一次性全部写入,代码会更加简洁,比如:
import csv
# 将所有数据存放在一个二维列表中
data = [
[1, '葡萄', '浆果', '夏', 27.3],
[2, '柿子', '浆果', '秋', 6.4],
[3, '橘子', '浆果', '秋', 11.9]
]
with open('data/fruits.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
# 一次性批量写入多行数据
writer.writerows(data)使用 pandas 库写入 CSV 文件
在 Python 中,我们还可以使用 pandas 库的 to_csv() 方法将数据导出到一个 CSV 文件。注意,to_csv() 是 DataFrame 对象的一个方法。
语法:
df.to_csv(path, index=布尔值 , header=布尔值)说明:
to_csv() 方法接收以下 3 个参数。
path(必选):表示文件的路径。index(可选):表示是否输出行名,默认值为 True(也就是会输出行名)。header(可选):表示是否输出列名,默认值为 True(也就是会输出列名)。
小伙伴们特别清楚一点:上一节介绍的 read_csv() 是 Pandas 的一个函数,而 to_csv() 是 DataFrame 的一个方法。接下来,我们清空 data 这个文件夹,此时整个项目结构如下图所示。
示例 3:pandas 写入 CSV
import pandas as pd
data = [
[1,'葡萄', '浆果', '夏', 27.3],
[2,'柿子', '浆果', '秋', 6.4],
[3,'橘子', '浆果', '秋', 11.9],
[4,'山竹', '仁果', '夏', 40.0],
[5,'苹果', '仁果', '秋', 12.6],
]
df = pd.DataFrame(data, columns=['id', 'name', 'type', 'season', 'price'])
df.to_csv('data/fruits.csv')运行代码之后,我们可以发现 data 文件夹中多了一个 fruits.csv 文件,如下图 1 所示。fruits.csv 文件内容如图 2 所示。
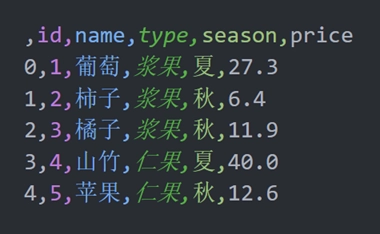
分析:
上面其实是把行名也写进来了,很多时候我们并不希望 CSV 文件有这种连续整数的行名,此时可以使用 index=False 这个参数,代码修改如下。
df.to_csv('data/fruits.csv', index=False)再次运行代码之后,打开 fruits.csv,此时发现行名不见了,如下图所示。

提示: Pandas 是 Python 数据分析最重要的工具之一,想要更全面深入地了解它,可以学习我们即将上线的 Pandas 教程。
